
Velocidade Máxima na Impressora 3D
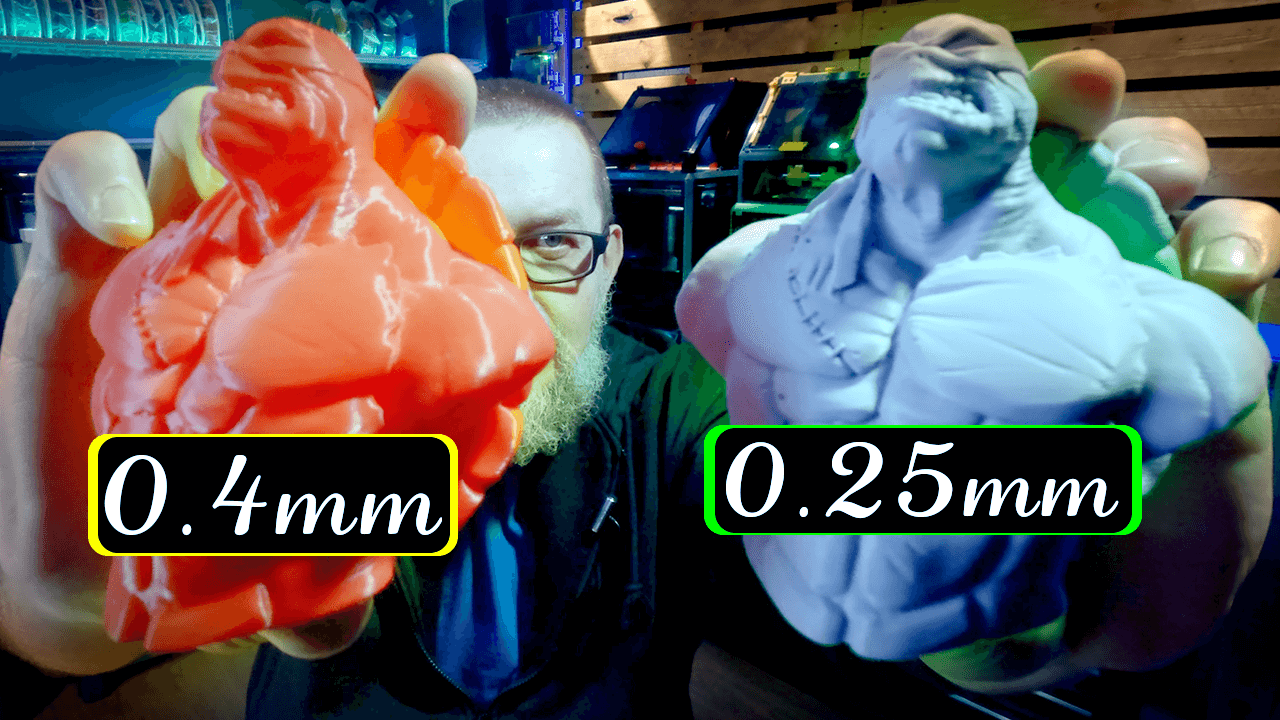
Impressões 3D Ultra Detalhadas

BambuLab X1 Carbon: Análise Completa

Impressão 3D Mais Rápida: Testando o Bico de 0.8mm

Creality K1C: Usei, testei e analisei em detalhes!

Impressora 3D: Como Aumentar a Velocidade sem Perder Qualidade

PLA Dynalabs | Filamento Premium

Creality Print 5.1 Review

Minha Farm 3D

Domine o Benchy e Tenha uma Impressão 3D Perfeita!
Neste vídeo, vou te apresentar a evolução do SQL como Banco de Dados Relacional e como ele vem sendo substituído pelos Bancos de Dados NoSQL. Além disso, você conhecerá um novo conceito que é o Banco de Dados de Grafo (GraphDB) e quais são as soluções que ele vem trazendo para demandas de alta performance, escalabilidade, integridade e relacionamentos!
Também vou abordar conceitos do Apache TinkerPop, Amazon Neptune, linguagem Gremlin, Cassandra DB, Arango DB, Dynamo DB entre outros.
🎯 Links de outros vídeos que já fiz sobre Banco de Dados:
– Banco de Dados NoSQL – Vantagens e Desvantagens – https://youtu.be/fySiDsKVZY0
– Banco de Dados Relacional – https://youtu.be/6SVwygschaM
– AWS RDS Aurora criando Banco de Dados MySQL – https://youtu.be/QIYJ3bFnmIQ
Gostou do conteúdo deste vídeo?
👍 Então deixa um comentário, dá um like e Inscreva-se!
Tá sem tempo pra assistir o “Um Inventor Qualquer? Você pode ouvir!
Estamos em todas as plataformas de podcast!
🎧 Ouça aqui: https://www.uminventorqualquer.com.br/podcast/
Quer ficar por dentro das novidades que estamos preparando para o canal?
📸 Nos siga no Instagram: https://www.instagram.com/uminventorqualquer
Nossas redes sociais:
Facebook: https://www.facebook.com/uminventorqualquer
Instagram: https://www.instagram.com/uminventorqualquer
Twitter: https://twitter.com/uminventorqquer
Blog: https://www.uminventorqualquer.com.br
Podcasts: https://uminventorqualquer.captivate.fm/
Está sem tempo para assistir ao Vídeo ou ouvir nosso Podcast? Sem problemas, abaixo você poderá ler a Legenda do vídeo! Ah... elas são geradas automaticamente 😉
Eu acho que exagerei um pouquinho mas esse é um vídeo onde eu vou falar para você porque que o SQL tá morrendo mas quem é que vai tomar um lugar da linguagem de requisição a banco de dados ou query language mais usada no mundo a gente ainda não sabe mas você vai poder ter algumas pistas nesse vídeo fica ligado aí [Música] o que está acontecendo com SQL não é de agora tá é uma coisa que vem acontecendo durante muitos anos ou nas últimas décadas basicamente porque as tecnologias se substituem o elas evoluem até o ponto em que elas não conseguem mais e em determinado momento elas são substituídas por outras tecnologias mais modernas ou tecnologias que atendem demandas mais modernas do mercado e o SQL tá mais ou menos nessa vibe mas para você entender exatamente a história do SQL e poder imaginar aonde ela vai acabar eu preciso contar um pouquinho sobre como ela começou lá atrás O SQL que hoje é a linguagem de bancos de dados mais utilizadas no mundo nasceu como um conceito como qualquer outra linguagem ou qualquer outra tecnologia esse conceito foi sendo aplicado em Sistemas que vinham com o objetivo de armazenar E servir como consulta para dados que precisavam ser armazenados ao longo do tempo foram evoluindo e implementando novas features lá na década de 90 o primeiro banco de dados que eu utilizei chamava-se Paradox que já utilizava SQL mas ele nem sequer era um banco de dados client-server ele era um banco de dados local mas o Paradox foi o primeiro banco de dados que eu aprendi a trabalhar e ele não era cliente-servidor ele ficava dentro de um arquivo na própria máquina onde a aplicação rodava quando começou a onda do client-server eu passei a utilizar interbase mas naquela época existia um problema muito grave que os bancos relacionais tentavam resolver que era a questão da integridade dos dados principalmente na concorrência de leitura e gravação aonde mais de uma máquina dentro da rede podia tá tentando ler e gravar ao mesmo tempo mesmo tempo um mesmo registro dentro do banco isso era crítico e era uma das missões do banco de dados relacional já que se fosse para você não ter essa integridade bastava você e gravar arquivos de texto gravados no disco O problema é que quando mais de um usuário Lia aquele arquivo alterava ele e tentava gravar de volta ao mesmo tempo em que outro usuário tentava fazer a mesma coisa eles poderiam ter duas versões diferentes e uma delas com certeza ia sobrepor à outra sem que eles ficassem sabendo que essa sobreposição existia porém com essa verificação de integridade os bancos relacionais começaram a se tornar cada vez mais engessados mais amarrados e eles começaram a criar todas essas travas e esses recursos para garantir a integridade dos dados essa integridade que naquela época foi a salvação de muitos desenvolvedores e de muitos sistemas que precisavam dessa integridade hoje tá sendo o tendão de Aquiles dos bancos relacionais por quê Porque para que você tenha esse alto nível de integridade na transação dos dados Você também precisa ter uma amarração ou um afunilamento das transações que entram no banco de dados e esse afunilamento acaba causando um problema que é ruim para a maioria dos sistemas de alta escalabilidade que hoje basicamente dominam o mundo da tecnologia Pois todos os sites e sistemas online hoje dependem de performance para poder entregar os dados ou serviços que eles desenvolvem pra um grande público e não mais para duas ou três máquinas dentro de uma redezinha interna das empresas hoje sistemas de ERP sistemas de controle contábil todos aqueles sistemas que lá na década de 90 funcionavam somente nas intranets hoje estão expostos na internet e podem ser acessados de qualquer lugar porém com isso vem a alta demanda E A alta demanda trava Justamente na questão do banco de dados mesmo falando de Cloud a gente consegue escalar as máquinas de aplicação basicamente de forma infinita você pode ir adicionando máquinas e suprindo a demanda dos seus usuários Porém quando a gente bate na camada de banco de dados essa camada é sempre o gargalo da aplicação e mesmo falando a nível de cloud computing os bancos relacionais também causam problemas pois essa verificação de integridade E A maneira como a arquitetura da engineering dos bancos relacionais foi desenvolvida ela foi feita para garantir a integridade e não a escalabilidade Então se mais de uma máquina cliente tenta acessar os mesmos registros ao mesmo tempo elas entram numa fila e cada uma delas é executada de uma vez só para que as outras que vem na sequência saibam o que elas estão alterando e para que esses dados não sejam sobrepostos essa arquitetura acaba causando esse afunilamento e é o que está causando a morte do SQL O SQL vem se tornando cada vez menos uma alternativa viável para sistemas de alta escalabilidade e qualquer um que vai montar uma Startup hoje em dia ou vai criar um sistema vai criar uma plataforma a escalar quer expandir para o país inteiro ou para o mundo inteiro para que a plataforma dele seja utilizada e claro dê retorno com SQL isso acaba virando um gargalo e um empecilho mesmo que você escale verticalmente você tem limite no tamanho das máquinas que você vai conseguir colocar dentro da sua infraestrutura em Cloud vai chegar o momento que você vai bater no teto quando chegar nesse momento você vai ter que começar a particionar sua base de dados colocando um determinado nicho de clientes no cluster um outro determinado lixo de cliente em outro cluster e isso começa a Gerar uma demanda tanto de atualização quanto de manutenção muito grande e acaba criando disparidade entre os sistemas mas quando a gente fala de uma plataforma onde você não pode segmentar os seus clientes por exemplo um Facebook da vida um Twitter ou qualquer outra plataforma Aonde a interação entre os clientes entre os usuários dessa plataforma é o que define a plataforma em si então os bancos relacionais ou bancos SQL acabam não sendo uma opção e acabam entrando um outro tipo de ferramenta nesse perfil ao longo do tempo em que o SQL se consolidou e ficou lá sentado no troninho dele como o rei das querys o rei das linguagens de bancos de dados outras tecnologias foram surgindo e foram tomando o lugar dele comendo pelas bordas e a mais utilizada delas chama-se banco NoSQL ou No SQL os bancos no SQL são bancos que obviamente não utilizam SQL são chamados no SQL por uma razão se liga mais os no SQL Ou NoSQLs são bancos de dados que oferecem alta performance porém uma das grandes diferenças entre os bancos NoSQL e os bancos SQL ou SQL é que os bancos SQL ou os bancos relacionais oferecem a integridade referencial por isso eles são chamados de bancos relacionais quando você tem duas tabelas que você precisa criar a referencia de dados entre essas duas tabelas você cria uma foreign key ou chave estrangeira que linka esses dados ou linka esses registros entre duas tabelas essas foreign key também podem ser definidas por constraints ou seja mecanismo de travamento ou de verificação de integridade Entre esses dados essas constraints não garantem só a integridade das informações quando elas são gravadas mas sim quando elas são manipuladas a partir do momento que você tem uma ligação você pode definir como essa ligação deve se comportar e caso você precise que os registros ou a integridade Entre esses registros seja mantida você pode impedir por exemplo que um registro pai seja deletado caso ele tenha registros filhos em outras tabelas ou você pode definir que quando esse registro Pai for deletado o sistema deve cascatear a deleção ou seja deve automaticamente Remover todas as dependências filhas desse registro principal essa verificação de integridade é retida e gerida pelo próprio banco de dados por isso o banco de dados relacional ou os bancos que utilizam SQL tem esta forte relação entre as entidades ou entre os registros de cada entidade que ele tem dentro dele por outro lado justamente essa questão da verificação da integridade é o que causa os gargalos no SQL e é o que não existe nos Bancos NoSQL que conseguem executar querys tanto de leitura quanto de gravação uma velocidade muito maior do que um banco SQL e com a vantagem o banco NoSQL ele pode ser escalado horizontalmente tendo várias máquinas Masters ou seja várias máquinas deste mesmo cluster podem aceitar gravações simultaneamente sem gerar conflito de registros é o caso do Cassandra por exemplo e o caso de vários outros sistemas de bancos de dados NoSQL que estão no mercado que tem essa capacidade de conseguir trabalhar com um cluster ou com uma replicação que chamamos de master master quando você tem uma read réplica no banco relacional essa réplica só pode ler ela é uma read replica quando você tem um banco NoSQL você consegue ter várias Master ou seja várias máquinas que permitem gravar os dados sem gerar conflito ou em alguns casos diminuindo drasticamente a possibilidade de conflito se você quiser saber um pouquinho mais sobre o banco NoSQL Eu fiz um vídeo algum tempo atrás aqui e você pode ver vou deixar o link aqui no card e vou deixar o link na descrição também lá eu falo especificamente sobre bancos NoSQL e também tem outro vídeo nosso falando sobre os bancos SQL Então você quer dar uma olhadinha lá eu vou deixar também o link na descrição e vou também deixar um outro link na descrição levando você para os nossos vídeos a respeito de RDS lá na Amazon que é o serviço da Amazon que oferece serviços de bancos de dados relacionais de formas gerenciado mas vamos lá o foco desse vídeo é a gente passar pela evolução dos bancos de dados e tentar imaginar quem é o candidato que vai substituir o SQL você Já adivinhou você já tá mais ou menos entendendo aonde eu quero chegar ainda não deixa aproveitar então enquanto você pensa para agradecer a todos os nossos inscritos e as pessoas que estão acompanhando o canal gente muito obrigado por vocês assistirem os vídeos por vocês darem like no vídeo por vocês compartilharem comentarem nos vídeos principalmente adoro responder comentários respondo a todos eles pelo menos ainda estou conseguindo responder mais o canal está crescendo e está crescendo Graças a vocês e eu agradeço demais o apoio de vocês demais ajuda de vocês com o canal porque o YouTube infelizmente não está recomendando o canal tanto quanto a gente gostaria e a única razão da gente está crescendo é Graças a vocês que recomendam o nosso canal que compartilham os vídeos e tudo mais então gente muito obrigado e eu agradeço de coração porque é isso que motiva a gente a continuar fazendo e gravando os vídeos no final de semana para poder publicar no canal porque de outra forma obviamente a gente não teria motivação para poder tá batalhando e conseguindo entregar esse conteúdo para vocês então mais uma vez muito obrigado voltando vamos lá saímos do SQL banco relacional eles tinham uma missão eles cumpriram muito bem a missão deles Porém para se manter na missão eles também precisavam se manter limitados porque as regras do banco relacional não podem ser alteradas simplesmente de uma hora para outra seria como o que aconteceu com o nosso amigo Angular que na versão um tinha uma sintaxe uma estrutura uma linguagem para você poder trabalhar nele e de repente quando foi para versão dois Tudo Mudou E A comunidade inteira ficou altamente frustrada com o Angular porque as aplicações antigas não podiam ser simplesmente atualizadas elas precisavam ser migradas re-desenvolvidas no novo formato do Angular E isso gerou uma certa frustração na comunidade porém o SQL é um caso mais grave ainda porque o SQL é um conceito mesmo e considerando que seja só um Framework você é gera frustração agora você quebrar um conceito inteiro que é o conceito de banco relacional para você poder se atualizar e atender a uma demanda nova de mercado é virtualmente uma baita sacanagem com quem trabalha com SQL você imagina só de repente vem sei lá Oracle, Postgrees, MySQL não importa vem algum mantenedor desses de bancos de dados relacionais e diz galera a partir da versão 5 nós não temos mais integridade referencial porque nós vamos priorizar a performance não ia ser nada agradável concorda comigo então o que acontece os bancos relacionais continuam focados no que eles fazem de melhor que a integridade referencial E A integridade de dados porém lá pela curva de Fora contornando por dentro, tentando entrar na frente dos bancos relacionais e em alguns momentos eu acredito que ele já tem até passado já tenha dado até uma volta em cima dos bancos relacionais vem os nossos amigos bancos de grafo exatamente e o que seria um banco de grafo banco de grafo é basicamente um conceito de banco de dados focados em relacionamento Espera aí se banco relacional é focado em relacionamento um banco de grafo é um banco relacional não Não exatamente ainda o que acontece com o banco de grafo é que ele foi desenhado e planejado para trabalhar com um nível de relacionamento muito mais profundo do que um banco SQL lá no SQL quando a gente quer fazer uma query que junta duas tabelas a gente faz um join esse join precisa ter especificado Quais são os campos que você vai comparar entre uma tabela e outra e vai fazer com que esses campos sejam iguais desde o registro que você tá pegando inicialmente na tabela a e fazendo a relação desses Campos com a tabela b c d ou quantas tabelas você precisa fazer mas quando você precisa fazer uma análise de relacionamento muito mais profunda Principalmente quando ela é recursiva por exemplo a pessoa a que é amiga da pessoa B que tem amizades com uma pessoa C D e E pode ter feito uma publicação nas suas redes sociais e eu quero saber dessas pessoas quem fez uma publicação e recebeu like dos amigos delas Já pensou na confusão e na complexidade que seria uma query como essa dentro de um banco relacional usando SQL para fazer join ou Sub querys ou inner join left join ia virar um inferno E para piorar e se não tivesse limite para a quantidade de saltos que você deveria dar nesses relacionamentos recursivos quantas vezes você poderia saltar para dentro desses relacionamentos dos amigos dos amigos dos amigos e verificar quais os posts receberam like das pessoas que estão no círculo de amizade daquela pessoa que fez o post tá dando nó na sua cabeça pois é na minha também e seria impossível fazer isso no banco SQL no banco relacional que utiliza SQL como linguagem e os bancos de grafo vieram para solucionar esse problema isso não é só um problema de redes sociais os bancos de grafos vieram para resolver problemas muito mais complexos como por exemplo análise antifraude para poder analisar os vínculos de relacionamento entre uma pessoa e o uso do cartão de crédito dela em vários estabelecimentos diferentes para analisar o tipo de produto que ela consome para saber se numa determinada Compra aquele cartão não foi utilizado por um terceiro para cometer uma fraude ou se o número do cartão foi roubado coisas desse tipo os bancos de grafo vão muito além da simples análise a ligação entre pessoas dentro de uma rede social e ele pode relacionar qualquer tipo de dado qualquer tipo de relacionamento entre entidades diferentes entre uma pessoa e um cartão de crédito entre uma pessoa e uma determinada marca de carro e assim por diante Além disso existem tecnologias Como o próprio Apache TinkerPop por exemplo que intermedia as requisições entre as aplicações e Bancos NoSQL para que eles sejam utilizados como bancos de grafo e ofereçam os mesmos recursos de um banco de grafo mas utilizando o seu banco NoSQL preferido como o Cassandra Arango DB uma série de outros bancos de dados que você pode utilizar atrás do seu banco de grafo digamos assim mas que você consegue gerenciar ou utilizar eles de maneira que você já está acostumado é o caso por exemplo do Dynamo DB que é um serviço escalável da Amazon e também é compatível com o Apache TinkerPop pode ser utilizado como uma base de dados e para uma plataforma de grafo e você pode explorar e utilizar ele com todas as vantagens de um banco de grafo convencional porém utilizando o banco NoSQL lá atrás tendo performance escalabilidade e autogerenciamento sem você precisar esquentar muito a cabeça mas Além disso é claro você tem vários serviços disponíveis aí no mercado em plataforma de cloud como a plataforma da Microsoft do Google e até do Alibaba já desenvolveu o banco de grafo proprietário para oferecer dentro da infraestrutura deles é Amazon não fica para trás porque Amazon oferece um banco de grafo chamado Neptune que é compatível com a linguagem Gremlin do Apache TinkerPop e que permite você fazer essas interações em formato grafo porém persistindo os dados no S3 oferecendo persistência múltipla de informações redundância alta escalabilidade e uma série de outros recursos que são extremamente importantes quando você tá trabalhando com aplicações que precisam de escalabildade ou que vão precisar de escalabilidade no futuro no próximo vídeo eu vou mostrar para vocês como eu desenvolvi um conector para fazer a integração entre um ORM de um Framework padrão e a sintaxe da linguagem do Gremlin que é a linguagem de banco de grafo do Apache TinkerPop e também nesse vídeo do connector eu vou dar dicas para vocês super importantes de como vocês podem se motivar a aprender mais desenvolvendo o código para a comunidade Opensource então fica ligado se inscreve deixa o like deixe o comentário ajuda o canal compartilhando esse vídeo com seus amigos e fica ligado no próximo vídeo porque vai ser muito legal a gente falar sobre o conector e sobre o Gremlin Especialmente para quem tá ainda meio travado com relação a projetos Paralelos OK tá ligado aí vou deixar Dois videozinhos aqui para vocês para vocês não fugirem do canal e mais uma vez muito obrigado um grande abraço e até a próxima